1 导入
- pandas在底层大量使用了 numpy 数组来存储数据
- 一种高效的滚动计算方式(这里用循环示意,实际有更高效的函数如
np.lib.stride_tricks.sliding_window_view)rolling_max = np.array([np.max(prices[i:i+window]) for i in range(len(prices) - window + 1)])
Series: 一维数据/单行
1.1 创建DataFrame
2 初识 DataFrame
<class 'pandas.core.frame.DataFrame'>
(1256, 37)
Index(['代码', '名称', '最新价', 'IOPV实时估值', '基金折价率', '涨跌额', '涨跌幅', '成交量', '成交额',
'开盘价', '最高价', '最低价', '昨收', '振幅', '换手率', '量比', '委比', '外盘', '内盘',
'主力净流入-净额', '主力净流入-净占比', '超大单净流入-净额', '超大单净流入-净占比', '大单净流入-净额',
'大单净流入-净占比', '中单净流入-净额', '中单净流入-净占比', '小单净流入-净额', '小单净流入-净占比', '现手',
'买一', '卖一', '最新份额', '流通市值', '总市值', '数据日期', '更新时间'],
dtype='object')
代码 object
名称 object
最新价 float64
IOPV实时估值 float64
基金折价率 float64
涨跌额 float64
涨跌幅 float64
成交量 float64
成交额 float64
开盘价 float64
最高价 float64
最低价 float64
昨收 float64
振幅 float64
换手率 float64
量比 float64
委比 float64
外盘 float64
内盘 float64
主力净流入-净额 float64
主力净流入-净占比 float64
超大单净流入-净额 float64
超大单净流入-净占比 float64
大单净流入-净额 float64
大单净流入-净占比 float64
中单净流入-净额 float64
中单净流入-净占比 float64
小单净流入-净额 float64
小单净流入-净占比 float64
现手 float64
买一 float64
卖一 float64
最新份额 float64
流通市值 int64
总市值 int64
数据日期 datetime64[ns]
更新时间 datetime64[ns, Asia/Shanghai]
dtype: object
代码 名称 最新价 IOPV实时估值 基金折价率 涨跌额 涨跌幅 成交量 \
0 560660 云50ETF 1.993 1.9837 -0.47 0.077 4.02 383192.0
1 516700 大数据产业ETF 1.150 1.1460 -0.35 0.040 3.60 347050.0
2 159890 云计算ETF 1.757 1.7517 -0.30 0.061 3.60 434843.0
成交额 开盘价 ... 小单净流入-净额 小单净流入-净占比 现手 买一 卖一 \
0 75804746.0 1.907 ... 4039944.0 5.33 -16.0 1.993 1.994
1 39940607.0 1.111 ... 5320233.0 13.32 -22.0 1.150 1.151
2 75962752.4 1.698 ... -2195449.0 -2.89 2359.0 1.756 1.757
最新份额 流通市值 总市值 数据日期 更新时间
0 76969000.0 153399217 153399217 2025-09-25 2025-09-25 16:11:53+08:00
1 73122000.0 84090300 84090300 2025-09-25 2025-09-25 16:11:48+08:00
2 266590688.0 468399839 468399839 2025-09-25 2025-09-25 15:34:48+08:00
[3 rows x 37 columns]
代码 名称 最新价 IOPV实时估值 基金折价率 涨跌额 涨跌幅 成交量 \
1253 159542 工程机械ETF 1.328 1.3285 0.04 -0.021 -1.56 40417.0
1254 520890 港股通红利低波ETF 1.379 1.3789 -0.01 -0.023 -1.64 295061.0
1255 513690 港股红利ETF博时 1.057 1.0609 0.37 -0.019 -1.77 1764256.0
成交额 开盘价 ... 小单净流入-净额 小单净流入-净占比 现手 买一 卖一 \
1253 5383487.8 1.346 ... 558462.0 10.37 -113.0 1.332 1.339
1254 40928756.0 1.402 ... 886906.0 2.17 99.0 1.379 1.380
1255 187689048.0 1.075 ... 2380478.0 1.27 31.0 1.056 1.057
最新份额 流通市值 总市值 数据日期 \
1253 9.592850e+06 12739305 12739305 2025-09-25
1254 5.850800e+07 80682532 80682532 2025-09-25
1255 4.969480e+09 5252740292 5252740292 2025-09-25
更新时间
1253 2025-09-25 15:34:12+08:00
1254 2025-09-25 16:11:33+08:00
1255 2025-09-25 16:11:39+08:00
[3 rows x 37 columns]
代码 名称 最新价 IOPV实时估值 基金折价率 涨跌额 涨跌幅 成交量 \
435 512360 MSCI中国A股ETF基金 1.772 1.7720 0.00 0.015 0.85 2552.0
101 159855 影视ETF 1.043 1.0433 0.03 0.020 1.96 181610.0
51 159805 传媒ETF 1.518 1.5126 -0.36 0.035 2.36 158526.0
63 562300 碳中和ETF基金 0.739 0.7379 -0.15 0.016 2.21 13867.0
1151 512730 银行ETF指数 1.615 1.6119 -0.19 -0.011 -0.68 86218.0
成交额 开盘价 ... 小单净流入-净额 小单净流入-净占比 现手 买一 卖一 \
435 4.503950e+05 1.760 ... -271857.0 -60.36 16.0 1.763 1.781
101 1.887999e+07 1.024 ... -2223657.0 -11.78 -1083.0 1.043 1.044
51 2.398655e+07 1.484 ... 410783.0 1.71 -1207.0 1.518 1.523
63 1.023450e+06 0.724 ... -56379.0 -5.51 2.0 0.737 0.739
1151 1.387661e+07 1.623 ... 2586206.0 18.64 10.0 1.614 1.615
最新份额 流通市值 总市值 数据日期 更新时间
435 36337700.0 64390404 64390404 2025-09-25 2025-09-25 16:11:56+08:00
101 105925236.0 110480021 110480021 2025-09-25 2025-09-25 15:34:36+08:00
51 109952480.0 166907865 166907865 2025-09-25 2025-09-25 15:34:54+08:00
63 93495000.0 69092805 69092805 2025-09-25 2025-09-25 16:11:43+08:00
1151 83583900.0 134987999 134987999 2025-09-25 2025-09-25 16:11:40+08:00
[5 rows x 37 columns]- 1, DataFrame格式
- 2, 属性和方法: shape, columns, dtypes, head, tail, sample
3 选择列与行
# 按列名选择(根据实际列名自动过滤)
maybe_cols = [c for c in ['代码', '名称', '最新价', '涨跌幅', '成交额', '成交量'] if c in data.columns]
data[maybe_cols].head()
data[['代码', '名称']].sample(3)
# iloc 按位置
data.iloc[0] # 第一行
data.iloc[:5, :3] # 前5行,前3列
# loc 按标签(示例:选择“涨跌幅”>0 的行)
cols = [c for c in ['代码', '名称', '涨跌幅'] if c in data.columns]
if '涨跌幅' in data.columns and cols:
data.loc[data['涨跌幅'] > 0, cols].head()- 是否使用
.iloc的效果一般一样, 但.iloc更明确, 且直接索引data[-3:,2]会报错, 而data.iloc[-3:,2]正常- 且会和
data['名称']引起歧义(虽然是pandas内部自动推断/更智能) - 且列名为整数时可能切列而非行
data[-3:]是 Pandas 的语法糖
- 且会和
data['涨跌幅'] > 0也返回一个Series, 且是布尔值data2[[True, False, True]]
4 条件筛选与排序
| 代码 | 名称 | 最新价 | IOPV实时估值 | 基金折价率 | 涨跌额 | 涨跌幅 | 成交量 | 成交额 | 开盘价 | ... | 小单净流入-净额 | 小单净流入-净占比 | 现手 | 买一 | 卖一 | 最新份额 | 流通市值 | 总市值 | 数据日期 | 更新时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 309 | 513330 | 恒生互联网ETF | 0.608 | 0.6065 | -0.25 | 0.007 | 1.16 | 114604542.0 | 6.981604e+09 | 0.602 | ... | 2073206.0 | 0.03 | 982.0 | 0.607 | 0.608 | 5.756748e+10 | 35001027879 | 35001027879 | 2025-09-25 | 2025-09-25 16:11:35+08:00 |
| 292 | 513130 | 恒生科技ETF | 0.848 | 0.8474 | -0.07 | 0.010 | 1.19 | 87556173.0 | 7.420435e+09 | 0.838 | ... | -1822677.0 | -0.02 | -6011.0 | 0.848 | 0.849 | 4.860135e+10 | 41213942317 | 41213942317 | 2025-09-25 | 2025-09-25 16:11:44+08:00 |
| 253 | 513180 | 恒生科技指数ETF | 0.865 | 0.8626 | -0.28 | 0.011 | 1.29 | 81492707.0 | 7.041300e+09 | 0.854 | ... | -2344514.0 | -0.03 | 2565.0 | 0.864 | 0.865 | 5.175976e+10 | 44772192068 | 44772192068 | 2025-09-25 | 2025-09-25 16:11:55+08:00 |
3 rows × 37 columns
[False, True][:len(keys)]这段过于防御性编程了…- 1, 核心1:
sort_values(by=) - 2, 核心2: 不能用and, 要用
&
5 新增/变换列
# 示例:把“涨跌幅(%)”转换为小数(若原本是百分比)
data['涨跌幅_小数'] = data['涨跌幅'] / 100.0 if data['涨跌幅'].abs().max() > 1 else data['涨跌幅']
# 示例:估算涨跌幅
data['估算涨跌幅'] = (data['最新价'] / data['开盘价'] - 1).replace([np.inf, -np.inf], np.nan)
# 条件列:大成交量标记
data['是否大成交量'] = np.where(data['成交量'] > 5e8, '是', '否')
# 字段重命名(演示)
data_renamed = data.rename(columns={'最新价': 'price', '涨跌幅': 'pct_chg'})
data_renamed.head(3)| 代码 | 名称 | price | IOPV实时估值 | 基金折价率 | 涨跌额 | pct_chg | 成交量 | 成交额 | 开盘价 | ... | 买一 | 卖一 | 最新份额 | 流通市值 | 总市值 | 数据日期 | 更新时间 | 涨跌幅_小数 | 估算涨跌幅 | 是否大成交量 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 560660 | 云50ETF | 1.993 | 1.9837 | -0.47 | 0.077 | 4.02 | 383192.0 | 75804746.0 | 1.907 | ... | 1.993 | 1.994 | 76969000.0 | 153399217 | 153399217 | 2025-09-25 | 2025-09-25 16:11:53+08:00 | 0.0402 | 0.045097 | 否 |
| 1 | 516700 | 大数据产业ETF | 1.150 | 1.1460 | -0.35 | 0.040 | 3.60 | 347050.0 | 39940607.0 | 1.111 | ... | 1.150 | 1.151 | 73122000.0 | 84090300 | 84090300 | 2025-09-25 | 2025-09-25 16:11:48+08:00 | 0.0360 | 0.035104 | 否 |
| 2 | 159890 | 云计算ETF | 1.757 | 1.7517 | -0.30 | 0.061 | 3.60 | 434843.0 | 75962752.4 | 1.698 | ... | 1.756 | 1.757 | 266590688.0 | 468399839 | 468399839 | 2025-09-25 | 2025-09-25 15:34:48+08:00 | 0.0360 | 0.034747 | 否 |
3 rows × 40 columns
- 1,
replace: 替换一系列值为nan - 2, 虽然记忆量不算高, 但一个cheatsheet对于新手期还是有必要的
6 汇总统计与分组聚合
# 全局描述统计
data.describe(include='all')
# 单列统计
data['最新价'].describe()
# 分组聚合(按“板块/主题/基金公司/ETF类型”等可用列)
group_col = None
for c in ['板块', '主题', '基金公司', '跟踪指数', 'ETF类型']:
if c in data.columns:
group_col = c
break
if group_col and '成交额' in data.columns:
agg_df = (data.groupby(group_col, dropna=False)
.agg(基金数=('代码', 'nunique') if '代码' in data.columns else ('名称', 'count'),
成交额合计=('成交额', 'sum'),
成交额均值=('成交额', 'mean'))
.sort_values('成交额合计', ascending=False))
agg_df.head(10)- 1,
describe: 快速统计 - 2,
groupby
7 透视表与交叉表
# 透视表:行=基金公司,列=是否大成交额,值=成交额合计
if set(['基金公司', '是否大成交额', '成交额']).issubset(data.columns):
pivot = pd.pivot_table(
data,
index='基金公司',
columns='是否大成交额',
values='成交额',
aggfunc='sum',
fill_value=0
)
pivot.head(10)
# 交叉表:计数
if set(['基金公司', '是否大成交额']).issubset(data.columns):
ctab = pd.crosstab(data['基金公司'], data['是否大成交额'])
ctab.head()- 感想/笔记: 以上做法我完全能用python写出来 -> 用基础pandas写出来, 只不过这里更简洁/高明
- 即, 是个 vimgulf 一样的’最短竞赛’游戏
7.0.1 关于简洁与优雅
- 但过于追求简洁,可读性差
8 缺失值处理
# 缺失概览
data.isna().sum().sort_values(ascending=False)
# 填充示例
filled = data.copy()
for col in filled.select_dtypes(include=[np.number]).columns:
filled[col] = filled[col].fillna(filled[col].median())
for col in filled.select_dtypes(include=['object']).columns:
filled[col] = filled[col].fillna('未知')
filled.head(3)| 代码 | 名称 | 最新价 | IOPV实时估值 | 基金折价率 | 涨跌额 | 涨跌幅 | 成交量 | 成交额 | 开盘价 | ... | 买一 | 卖一 | 最新份额 | 流通市值 | 总市值 | 数据日期 | 更新时间 | 涨跌幅_小数 | 估算涨跌幅 | 是否大成交量 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 560660 | 云50ETF | 1.993 | 1.9837 | -0.47 | 0.077 | 4.02 | 383192.0 | 75804746.0 | 1.907 | ... | 1.993 | 1.994 | 76969000.0 | 153399217 | 153399217 | 2025-09-25 | 2025-09-25 16:11:53+08:00 | 0.0402 | 0.045097 | 否 |
| 1 | 516700 | 大数据产业ETF | 1.150 | 1.1460 | -0.35 | 0.040 | 3.60 | 347050.0 | 39940607.0 | 1.111 | ... | 1.150 | 1.151 | 73122000.0 | 84090300 | 84090300 | 2025-09-25 | 2025-09-25 16:11:48+08:00 | 0.0360 | 0.035104 | 否 |
| 2 | 159890 | 云计算ETF | 1.757 | 1.7517 | -0.30 | 0.061 | 3.60 | 434843.0 | 75962752.4 | 1.698 | ... | 1.756 | 1.757 | 266590688.0 | 468399839 | 468399839 | 2025-09-25 | 2025-09-25 15:34:48+08:00 | 0.0360 | 0.034747 | 否 |
3 rows × 40 columns
- 向量化操作(比用循环逐列统计快得多)
8.0.1 关于魔法与天书
- 你的 Linux/算法竞赛/Vim 背景让你对这类系统有天然的亲和力
- 习惯了’用简洁工具表达复杂意图’的范式
- 学习曲线:记住模式而非细节(像学Vim快捷键)
- 背后的数学(真正的理解门槛)
- 涉及概率论、线性代数、统计推断
- 你只是在学:
- 新的语法糖和API设计
- 新的领域惯用法(金融数据分析)
- 新的工具生态(Pandas/NumPy 的协作方式)
- 无抵触 → 技术背景让你有正确的复杂度预期
9 字符串与类别列
# 字符串操作示例
if '名称' in data.columns:
s = data['名称'].astype(str)
demo = pd.DataFrame({
'原名': s.head(5),
'大写': s.str.upper().head(5),
'是否含科技': s.str.contains('科技', na=False).head(5),
'替换ETF': s.str.replace('ETF', '', regex=False).head(5)
})
demo
# 转类别类型(节省内存)
obj_cols = data.select_dtypes(include=['object']).columns[:5]
data_cat = data.copy()
for c in obj_cols:
data_cat[c] = data_cat[c].astype('category')
data_cat.dtypes.head(10)代码 category
名称 category
最新价 float64
IOPV实时估值 float64
基金折价率 float64
涨跌额 float64
涨跌幅 float64
成交量 float64
成交额 float64
开盘价 float64
dtype: objectdf['名称'].str.contains也是这类用法, ’字符串操作’专题下的用法
10 时间列与索引
# 如果有时间列,转换为 datetime,并设为索引
time_col = None
for c in ['日期', '时间', '更新时间']:
if c in data.columns:
time_col = c
break
if time_col:
df_time = data.copy()
df_time[time_col] = pd.to_datetime(df_time[time_col], errors='coerce')
df_time = df_time.set_index(time_col).sort_index()
df_time.index.inferred_type, df_time.head(3)
# 按天/小时重采样(如果是高频)
if df_time.index.inferred_type in ['datetime64', 'datetime64[ns]']:
if '最新价' in df_time.columns:
hourly = df_time['最新价'].resample('1h').mean()
hourly.head(5)resample: 重采样, 将高频数据(如每分钟)聚合为低频(如每小时)- 确保索引是时间类型后,才执行重采样(避免对非时间数据误操作)
pd.to_datetime()是 Pandas 中非常强大的时间解析工具,能自动转换多种格式的时间字符串或数字,包括常见的年月日、时间戳数字、甚至一些非标准格式- 关于索引 -> ‘为什么要设置索引呢? 不设置索引不是也能对所有列做排序操作吗’:
- 1, 排序只需一次,后续操作直接利用已排序的索引
- 2, 数据对齐与避免混淆: 假设df1和df2有相同的时间索引:
df1 + df2 - 3, 时间索引会自动成为 Matplotlib 图的X轴
11 合并与拼接
# 构造示例 company_df(按“代码”或“名称”关联)
keys = [k for k in ['代码', '名称'] if k in data.columns]
company_df = pd.DataFrame({
keys[0] if keys else '代码': data[keys[0]].head(5) if keys else range(5),
'评级': ['A', 'A', 'B', 'B', 'C']
})
# 左连接
merge_key = keys[0] if keys else None
if merge_key:
merged = pd.merge(data, company_df, how='left', on=merge_key)
merged.head(5)
# 纵向拼接(行叠加)
part1 = data.head(3)
part2 = data.tail(3)
concat_df = pd.concat([part1, part2], axis=0, ignore_index=True)
concat_df| 代码 | 名称 | 最新价 | IOPV实时估值 | 基金折价率 | 涨跌额 | 涨跌幅 | 成交量 | 成交额 | 开盘价 | ... | 买一 | 卖一 | 最新份额 | 流通市值 | 总市值 | 数据日期 | 更新时间 | 涨跌幅_小数 | 估算涨跌幅 | 是否大成交量 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 560660 | 云50ETF | 1.993 | 1.9837 | -0.47 | 0.077 | 4.02 | 383192.0 | 75804746.0 | 1.907 | ... | 1.993 | 1.994 | 7.696900e+07 | 153399217 | 153399217 | 2025-09-25 | 2025-09-25 16:11:53+08:00 | 0.0402 | 0.045097 | 否 |
| 1 | 516700 | 大数据产业ETF | 1.150 | 1.1460 | -0.35 | 0.040 | 3.60 | 347050.0 | 39940607.0 | 1.111 | ... | 1.150 | 1.151 | 7.312200e+07 | 84090300 | 84090300 | 2025-09-25 | 2025-09-25 16:11:48+08:00 | 0.0360 | 0.035104 | 否 |
| 2 | 159890 | 云计算ETF | 1.757 | 1.7517 | -0.30 | 0.061 | 3.60 | 434843.0 | 75962752.4 | 1.698 | ... | 1.756 | 1.757 | 2.665907e+08 | 468399839 | 468399839 | 2025-09-25 | 2025-09-25 15:34:48+08:00 | 0.0360 | 0.034747 | 否 |
| 3 | 159542 | 工程机械ETF | 1.328 | 1.3285 | 0.04 | -0.021 | -1.56 | 40417.0 | 5383487.8 | 1.346 | ... | 1.332 | 1.339 | 9.592850e+06 | 12739305 | 12739305 | 2025-09-25 | 2025-09-25 15:34:12+08:00 | -0.0156 | -0.013373 | 否 |
| 4 | 520890 | 港股通红利低波ETF | 1.379 | 1.3789 | -0.01 | -0.023 | -1.64 | 295061.0 | 40928756.0 | 1.402 | ... | 1.379 | 1.380 | 5.850800e+07 | 80682532 | 80682532 | 2025-09-25 | 2025-09-25 16:11:33+08:00 | -0.0164 | -0.016405 | 否 |
| 5 | 513690 | 港股红利ETF博时 | 1.057 | 1.0609 | 0.37 | -0.019 | -1.77 | 1764256.0 | 187689048.0 | 1.075 | ... | 1.056 | 1.057 | 4.969480e+09 | 5252740292 | 5252740292 | 2025-09-25 | 2025-09-25 16:11:39+08:00 | -0.0177 | -0.016744 | 否 |
6 rows × 40 columns
- 核心就在字面上:
合并, 要么上下相加(行下面再附加), 要么左右相加(列右边再附加)
12 可视化
import matplotlib.pyplot as plt
from trade_utils import apply_chinese_font
apply_chinese_font()
# 简单条形图:成交额 Top10
if '成交额' in data.columns:
top10 = data.sort_values('成交额', ascending=False).head(10)
label_col = '名称' if '名称' in data.columns else ('代码' if '代码' in data.columns else None)
if label_col:
plt.figure(figsize=(10, 5))
plt.bar(top10[label_col].astype(str), top10['成交额']/1e8)
plt.xticks(rotation=45, ha='right')
plt.ylabel('成交额(亿元)')
plt.title('ETF 成交额 Top10')
plt.tight_layout()
plt.show()
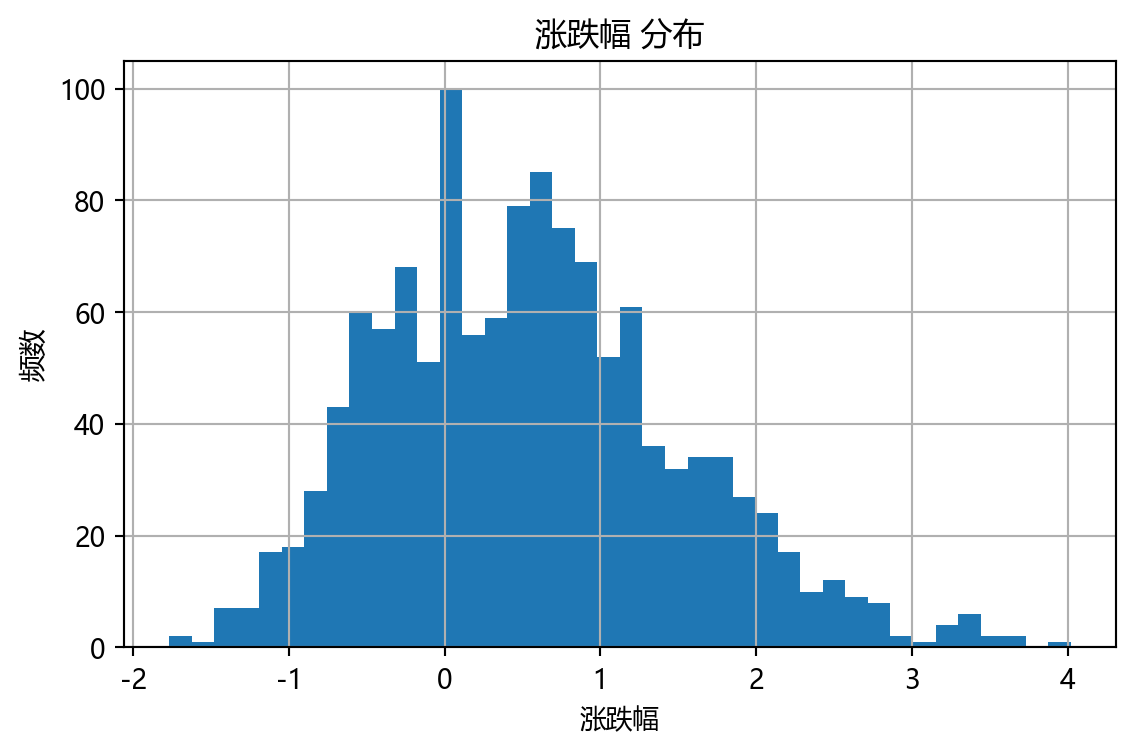
# 涨跌幅分布直方图
col = '涨跌幅' if '涨跌幅' in data.columns else ('涨跌幅_小数' if '涨跌幅_小数' in data.columns else None)
if col:
plt.figure(figsize=(6,4))
ax = data[col].dropna().hist(bins=40)
plt.title(f'{col} 分布')
plt.xlabel(col)
plt.ylabel('频数')
plt.tight_layout()
plt.show()
plt.close()Matplotlib 中文字体设置: Microsoft YaHei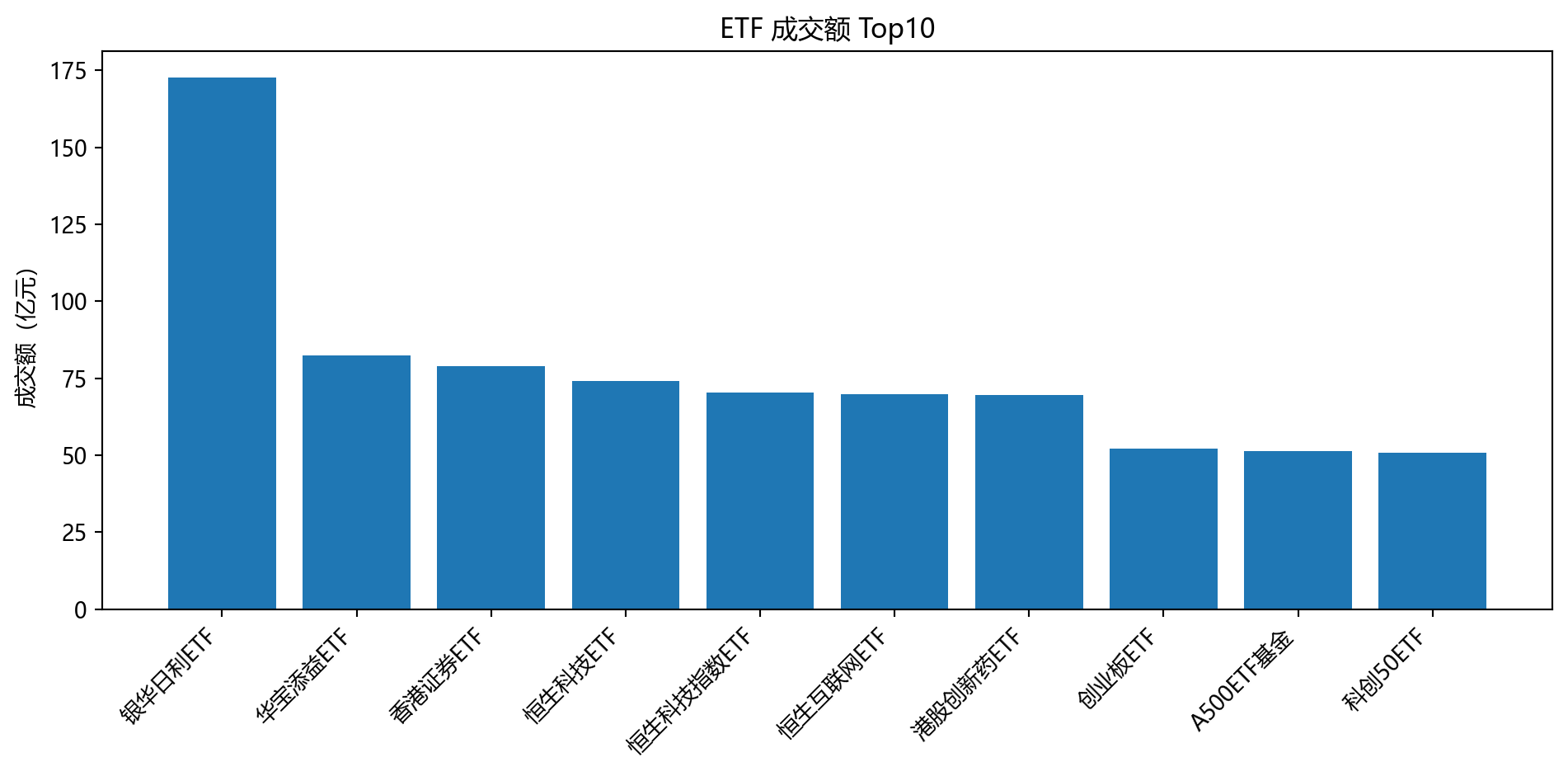
13 导出数据
提示:若列名为中文,尽量使用
data['列名']的方式访问,避免data.列名的歧义;运行前先用data.columns.tolist()确认实际列名。
14 对xtquant返回的dict格式三维数据进行操作
pandas下有array(一维)和dataframe(二维)
现在xtquant返回给我的数据格式是
{
'time': n x 315,
'open': n x 315,
...
}
这种格式, 内部是一个二维dataframe, n为请求时填入的不同标的
如何更好地操纵这种数据?- 转化为长格式:
- 1, 不要把每个标的单独存成一个 DataFrame -> 内存浪费、难以批量操作
- MultiIndex
- 最终存储的还是一个二维结构/二维dataframe
# 输出示例
open high low close
symbol time
000001.SZ 2023-01-02 10.500000 10.800000 10.400000 10.700000
2023-01-03 10.750000 11.000000 10.650000 10.950000
2023-01-04 10.900000 11.200000 10.850000 11.150000
600000.SH 2023-01-02 20.100000 20.500000 19.900000 20.300000
2023-01-03 20.400000 20.800000 20.200000 20.700000
...